
Natural Language Processing at CitizenLab: how machine learning can transform citizen engagement projects.
Will robots take over the world? Probably not. However, NLP (or Natural Language Processing) already has. In recent years, a technology that was hesitant at best has made a huge leap forward and is now being integrated into many of the services that we use everyday.
Of course, we wouldn’t be mentioning this if there wasn’t a link with civic tech. By making it easy to easily manipulate and process large amounts of text, NLP offers great potential for cities and governments who want to use input from citizens in decision-making. In this article, we’ll show you what NLP means, what it could mean for citizen participation and what you can expect in the years to come.
NLP, WTH ?
Natural Language Processing is a form of artificial intelligence (AI), which allows computers and code to process complex input previously only understandable by humans. NLP is a branch of AI that focuses on natural language – this means both written and spoken language used by human beings. Simply put, it analyses, understands and produces text. Here are a few examples where NLP is being used today:
- Text translators such as Google Translate or Deepl rely on machine learning to gain a better understanding of the text and provide a relevant translation which goes beyond simply translating word-per-word.
- Automated classification is used by most email providers to decide which emails are sent to your spam folder.
- Machine learning algorithms are used to predict the text you’re going to type and to suggest words in texts or emails.
Within the context of public decision making, NLP is typically all about making sense out of text. The technology can process text much faster than humans, which means it can quickly and easily extract meaningful insights from large amounts of data. This means that a city who collected thousands of contributions from citizens on a participation platform would be able to easily group together ideas and immediately see what main themes citizens talked about, what the main arguments are, and where the ideas were located throughout the city.
Setting up NLP processes
NLP relies on a dark, well-kept secret : technology can only get as good as the human reasoning behind it. This means that it’s essential to take great care in setting up natural language processing techniques. The initial descriptions you feed it and the databases you train it on will have a definitive influence; build it on flawed information and it will only ever give flawed results.
In the context of citizen participation platforms, here are two questions you should pay close attention to when building your algorithms:
- What’s the context? What is the text about – is it a cookbook, or a discussion about politics? Is it a long formal text, or short tweets with slang and emojis?
- What insights do you want to obtain? There are multiple end goals possible: some algorithms will summarise topics, some will look at emotional tendencies, some will work at identifying locations…
Once you’ve picked the methodology that best fits your needs, you’ll want to fine tune it. Why? The parameters used in your hand picked NLP algorithms need to be adapted to obtain accurate results for your context and for the natural language input you’ll use. Depending on the context, words can have different meanings. Think about the word “book”, for instance. It means something completely different when the text is about a library or when it’s about a hotel. Also, people may write or speak differently depending on the context: a newspaper article will not be written in the same tone as tweets.
As you train your algorithm on datasets, you’ll want to compare it to some manual output. Once the NLP results resemble the manual (‘perfect’) results, your algorithm is ready to be used. This resemblance is known as the ‘accuracy’ of your algorithm.
NLP is a very powerful tool, but we have to be honest – of course it’s not a perfect technology. You can’t blindly implement what it tells you. An accuracy of 100% is close to impossible to reach, meaning that there is always a risk to make mistakes and thus reach wrong conclusions. Therefore, the output of NLP technology should ideally be considered as a starting point, in need of some manual verification and good-old reasoning. If your technology is being used on a platform, it is extremely helpful to ask your users for their feedback and about the decisions they make based on the NLP output. Doing so will broaden and strengthen your training data and thus increase the accuracy of your NLP algorithms and keep them up to date.
Artificial intelligence in the context of citizen engagement
The main challenge in citizen participation projects isn’t to collect citizens’ input: it’s to analyse it. Overworked and under-resourced administrations often lack the time and technical skills to process the contributions; as a result, valuable insights get lost in the process. By helping administrations effortlessly process citizen input and extract the key ideas, NLP could help governments make better-informed decisions whilst saving time and money.
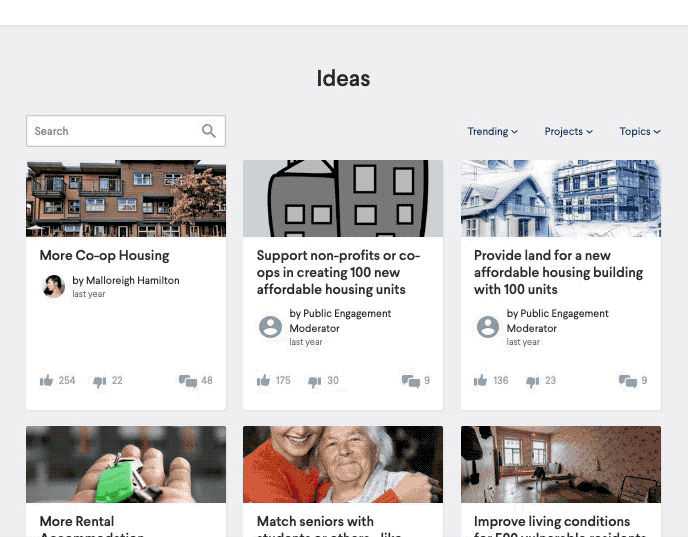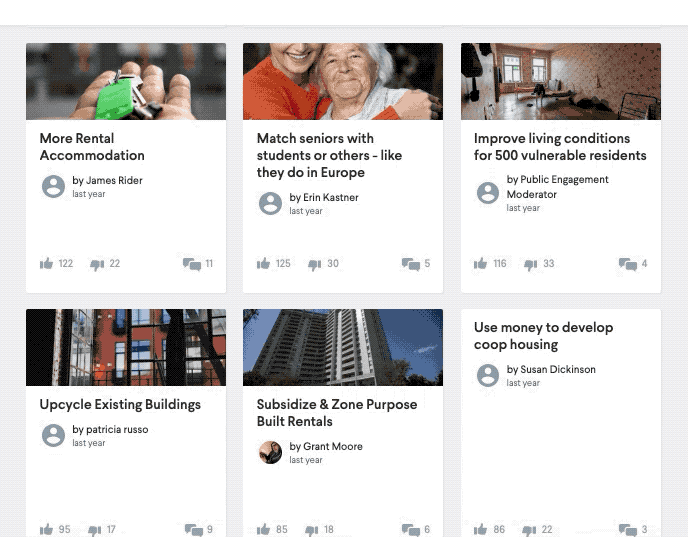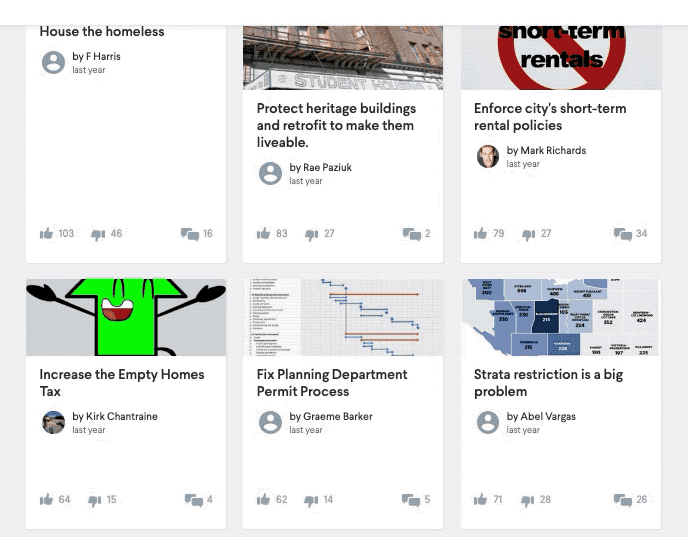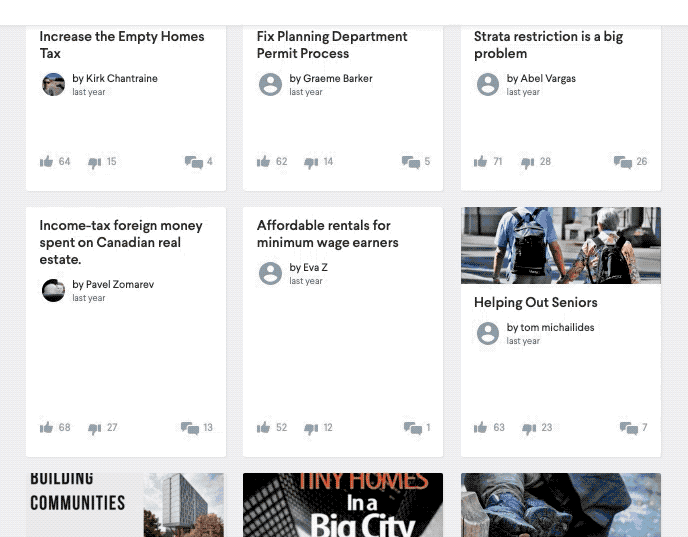
In order to help governments address this challenge we’ve integrated our own NLP technology to the CitizenLab platform, therefore giving civil servants a centralised place to gather, moderate and analyse citizens’ ideas. There are 4 main strands to the technology we have implemented, all focused on text analysis; ultimately, they all aim to reduce the effort involved in processing the data.
- Classification: in order to give some broad context to the debate, the organisation (city, federal government…) defines their own topics or classes up front (e.g. mobility, welfare, security). Every piece of citizen input then gets automatically added to one or more of these classes. Once done, administrators can easily reassign input to colleagues and discover what topics need most attention.
- Similarity: Every piece of citizen input gets compared to every other piece. The more words they have in common, the more similar they are – provided that the meaning of these words is the same. This avoids duplicate content and allows administrators to group users based on the similarity of their input, thus uncovering interesting patterns and insights. It could be that all elderly from a certain neighbourhood are talking about their need for more green and adapted infrastructure, or that young citizens from another neighbourhood are expressing a need for more social housing.

- NER: Named Entity Recognition is a type of NLP that links words or groups of words to another entity – in our case, recognising places that are mentioned in the comments and locating them on a map. Transforming a written street or city name to geo-coordinates is an obvious use case, but it also enables us to identify geographical ‘hot spots’, such as a park, church or hospital and add a location to it.
- Summarisation: Summarisation is the next natural step to take.It simply detects all key words or phrases in the contributions, and highlights the main ideas. This makes it easy to see the big picture before deciding to dive in.
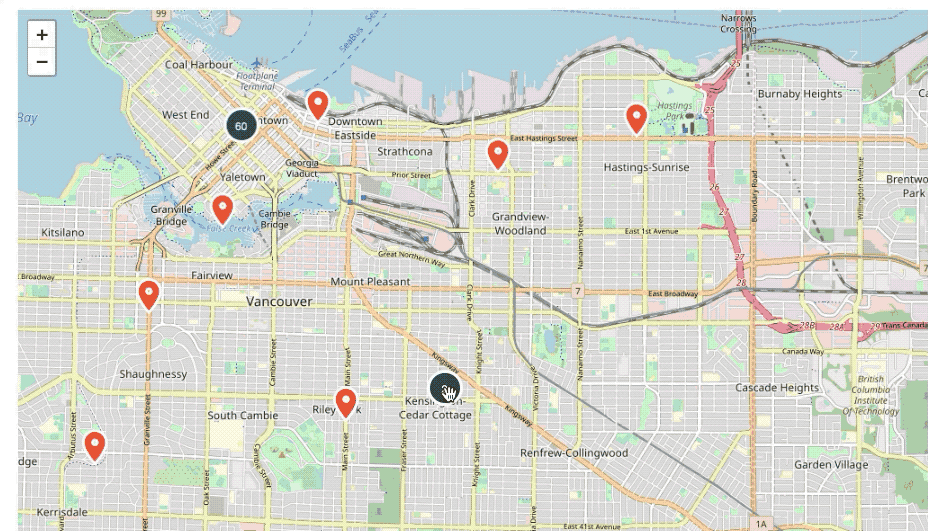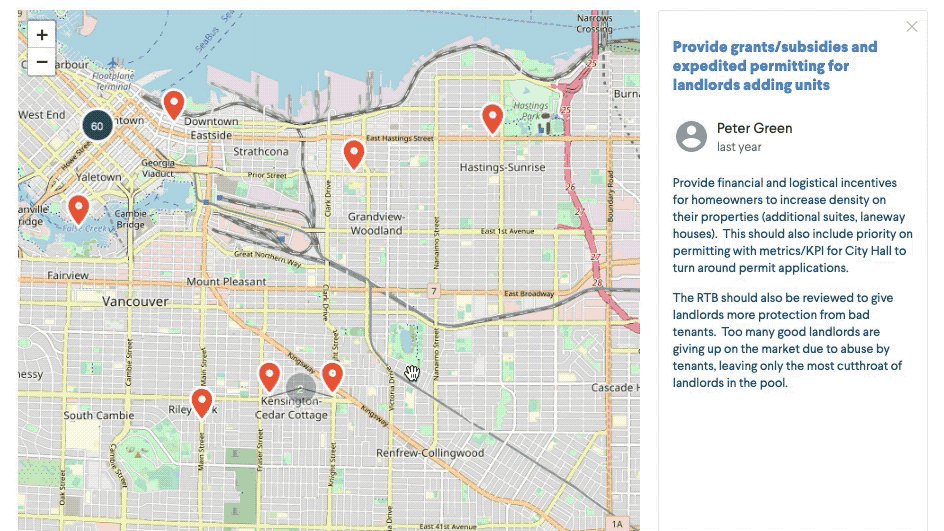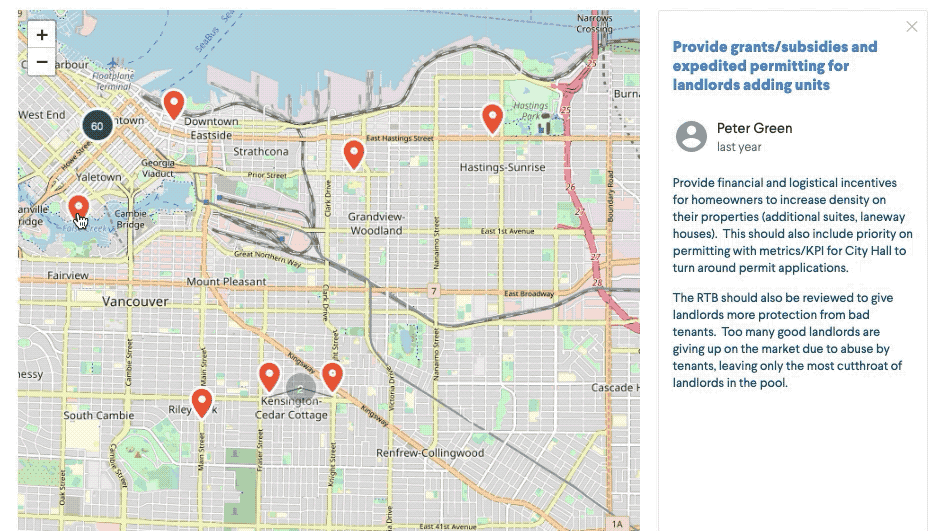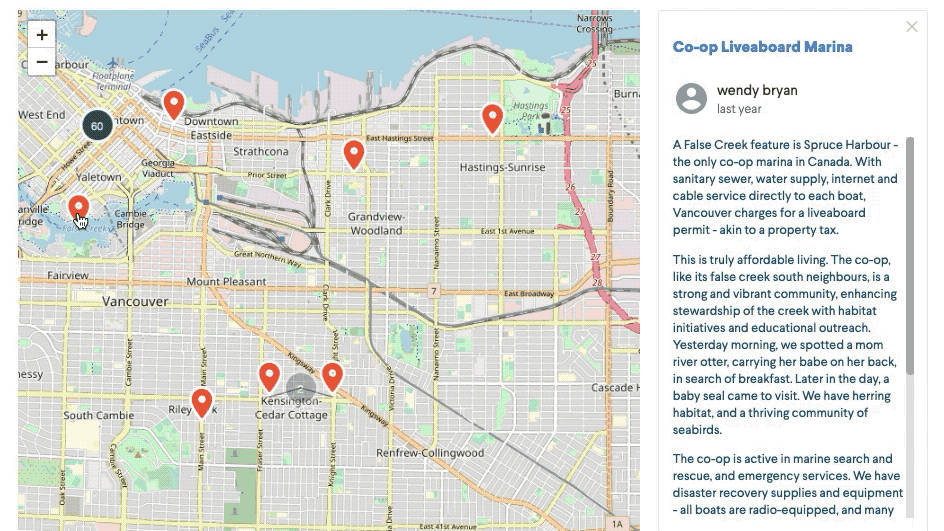
What’s next?
Does it stop there? Of course not! The ever-evolving world of NLP offers many more opportunities to enhance citizen participation and public decision making.
As Named Entity Recognition can spot locations and hot spots, NLP can also identify other ‘value’ in chunks of text. Most promising in the context of citizen participation are sentiment analysis, argument analysis and typology. As the wording suggests, sentiment analysis is a way to distill the dominant emotions in a piece of text. Is that person angry, sad or hopeful? Argument analysis is perfect to analyse a discussion which follows on an idea, suggestion or opinion and in which several people participate. It transforms each participant’s contribution to that discussion into a pro, counter or neutral argument and groups them accordingly. And lastly, a typology analysis identifies the type of text you’re looking at. Is it a suggestion, a question, a complaint, a response to a previous comment… All of these further details will help administrations get a finer perception of what citizens are saying and adapt their response accordingly.
For CitizenLab, another big step to take is widening the scope of our current NLP technologies. As of today it focuses on citizens’ written input, with its own specifics. In the future, that same technology could be applied to other types of input: strategic city plans, city budgets, speeches of local decision makers, council agendas and decisions, local news articles … you name it. The objective here would be to close the loop. A citizen posting an idea about bike lanes in the city center, could also discover what the mayor has previously said about it, what has been planned on this topic in the next city council meeting and how the current data on biking look like.
Finally, one of the main challenges we face is the human factor behind the technology. Governments are a sector where it can be difficult and slow to implement change. We know that the best of platforms with the most powerful algorithms will only truly work if it is understood and embraced by civil servants. In order to solve this issue, we have been awarded one of Nesta’s Collective Intelligence Grants, and will use the funds to research how artificial intelligence is currently used in governments. If you’re interested, we’ve written more extensively about this opportunity here.
About the author

Wietse Van Ransbeeck
CEO
CitizenLab
The article was originally published at CitizenLab